Pengklasifikasian menggunakan teorema Naive Bayes
Mendefinisikan Kumpulan Data
Dalam contoh ini, Anda dapat menggunakan kumpulan data dummy dengan tiga kolom: cuaca, suhu, dan permainan. Dua yang pertama adalah fitur (cuaca, suhu) dan yang lainnya adalah label.
# Assigning features and label variables
weather=['Sunny','Sunny','Overcast','Rainy','Rainy','Rainy','Overcast','Sunny','Sunny',
'Rainy','Sunny','Overcast','Overcast','Rainy']
temp=['Hot','Hot','Hot','Mild','Cool','Cool','Cool','Mild','Cool','Mild','Mild','Mild','Hot','Mild']
play=['No','No','Yes','Yes','Yes','No','Yes','No','Yes','Yes','Yes','Yes','Yes','No']
Fitur Pengkodean
Pertama, Anda perlu mengubah label string ini menjadi angka. misalnya: 'Mendung', 'Hujan', 'Cerah' sebagai 0, 1, 2. Ini dikenal sebagai penyandian label. Scikit-learn menyediakan perpustakaan LabelEncoder untuk menyandikan label dengan nilai antara 0 dan satu kurang dari jumlah kelas diskrit.
# Import LabelEncoder
from sklearn import preprocessing
#creating labelEncoder
le = preprocessing.LabelEncoder()
# Converting string labels into numbers.
wheather_encoded=le.fit_transform(wheather)
print wheather_encoded
[2 2 0 1 1 1 0 2 2 1 2 0 0 1]
Demikian pula, Anda juga dapat menyandikan kolom temp dan play.
# Converting string labels into numbers
temp_encoded=le.fit_transform(temp)
label=le.fit_transform(play)
print "Temp:",temp_encoded
print "Play:",label
Temp: [1 1 1 2 0 0 0 2 0 2 2 2 1 2]
Play: [0 0 1 1 1 0 1 0 1 1 1 1 1 0]
Sekarang gabungkan kedua fitur (cuaca dan suhu) dalam satu variabel (daftar tupel).
#Combinig weather and temp into single listof tuples
features=zip(weather_encoded,temp_encoded)
print features
[(2, 1), (2, 1), (0, 1), (1, 2), (1, 0), (1, 0), (0, 0), (2, 2), (2, 0), (1, 2), (2, 2), (0, 2), (0, 1), (1, 2)]
Menggenerasi Model
Hasilkan model menggunakan pengklasifikasi naive bayes dalam langkah-langkah berikut:
- Buat pengklasifikasi bayes naif
- Sesuaikan dataset pada classifier
- Lakukan prediksi
#Import Gaussian Naive Bayes model
from sklearn.naive_bayes import GaussianNB
#Create a Gaussian Classifier
model = GaussianNB()
# Train the model using the training sets
model.fit(features,label)
#Predict Output
predicted= model.predict([[0,2]]) # 0:Overcast, 2:Mild
print "Predicted Value:", predicted
Predicted Value: [1]
Di sini, 1 menunjukkan bahwa pemain dapat 'bermain'.
Naive Bayes dengan Banyak Label
Sampai sekarang Anda telah mempelajari klasifikasi Naive Bayes dengan label biner. Sekarang Anda akan belajar tentang klasifikasi kelas ganda di Naive Bayes. Yang dikenal dengan klasifikasi multinomial Naive Bayes. Misalnya, jika Anda ingin mengklasifikasikan artikel berita tentang teknologi, hiburan, politik, atau olahraga.
Di bagian pembuatan model, Anda dapat menggunakan dataset anggur yang merupakan masalah klasifikasi multi-kelas yang sangat terkenal. "Dataset ini adalah hasil dari analisis kimia anggur yang ditanam di wilayah yang sama di Italia tetapi berasal dari tiga kultivar yang berbeda." ( UC Irvin )
Dataset terdiri dari 13 fitur (alcohol, malic_acid, ash, alcalinity_of_ash, magnesium, total_phenols, flavanoids, nonflavanoid_phenols, proanthocyanin, color_intensity, hue, od280/od315_of_diluted_wines, proline) dan jenis kultivar wine. Data ini memiliki tiga jenis anggur Class_0, Class_1, dan Class_3. Di sini Anda dapat membangun model untuk mengklasifikasikan jenis anggur.
Dataset tersedia di perpustakaan scikit-learn.
Memuat Data
Pertama-tama mari kita muat dataset wine yang dibutuhkan dari dataset scikit-learn.
#Import scikit-learn dataset library
from sklearn import datasets
#Load dataset
wine = datasets.load_wine()
Menjelajahi Data
Anda dapat mencetak nama target dan fitur, untuk memastikan Anda memiliki kumpulan data yang benar, seperti:
# print the names of the 13 features
print "Features: ", wine.feature_names
# print the label type of wine(class_0, class_1, class_2)
print "Labels: ", wine.target_names
Features: ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
Labels: ['class_0' 'class_1' 'class_2']
Sebaiknya selalu jelajahi data Anda sedikit, jadi Anda tahu apa yang sedang Anda kerjakan. Di sini, Anda dapat melihat lima baris pertama dari kumpulan data dicetak, serta variabel target untuk seluruh kumpulan data.
# print data(feature)shape
wine.data.shape
(178L, 13L)
# print the wine data features (top 5 records)
print wine.data[0:5]
[[ 1.42300000e+01 1.71000000e+00 2.43000000e+00 1.56000000e+01
1.27000000e+02 2.80000000e+00 3.06000000e+00 2.80000000e-01
2.29000000e+00 5.64000000e+00 1.04000000e+00 3.92000000e+00
1.06500000e+03]
[ 1.32000000e+01 1.78000000e+00 2.14000000e+00 1.12000000e+01
1.00000000e+02 2.65000000e+00 2.76000000e+00 2.60000000e-01
1.28000000e+00 4.38000000e+00 1.05000000e+00 3.40000000e+00
1.05000000e+03]
[ 1.31600000e+01 2.36000000e+00 2.67000000e+00 1.86000000e+01
1.01000000e+02 2.80000000e+00 3.24000000e+00 3.00000000e-01
2.81000000e+00 5.68000000e+00 1.03000000e+00 3.17000000e+00
1.18500000e+03]
[ 1.43700000e+01 1.95000000e+00 2.50000000e+00 1.68000000e+01
1.13000000e+02 3.85000000e+00 3.49000000e+00 2.40000000e-01
2.18000000e+00 7.80000000e+00 8.60000000e-01 3.45000000e+00
1.48000000e+03]
[ 1.32400000e+01 2.59000000e+00 2.87000000e+00 2.10000000e+01
1.18000000e+02 2.80000000e+00 2.69000000e+00 3.90000000e-01
1.82000000e+00 4.32000000e+00 1.04000000e+00 2.93000000e+00
7.35000000e+02]]
# print the wine labels (0:Class_0, 1:class_2, 2:class_2)
print wine.target
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
Memisahkan Data
Pertama, Anda memisahkan kolom menjadi variabel dependen dan independen (atau fitur dan label). Kemudian Anda membagi variabel-variabel itu menjadi set kereta dan tes.
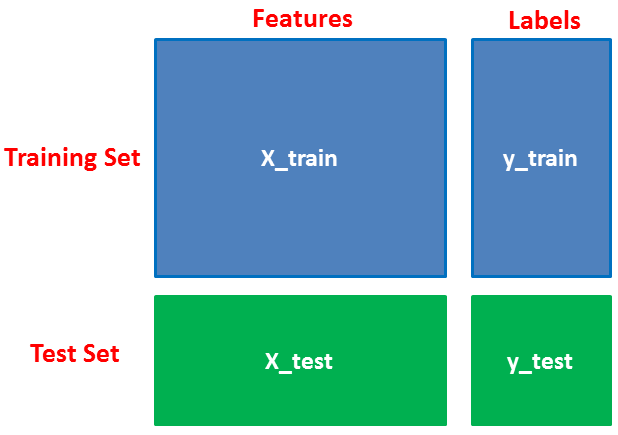
# Import train_test_split function
from sklearn.cross_validation import train_test_split
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3,random_state=109) # 70% training and 30% test
Generasi Model
Setelah pemisahan, Anda akan menghasilkan model hutan acak pada set pelatihan dan melakukan prediksi pada fitur set pengujian.
#Import Gaussian Naive Bayes model
from sklearn.naive_bayes import GaussianNB
#Create a Gaussian Classifier
gnb = GaussianNB()
#Train the model using the training sets
gnb.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = gnb.predict(X_test)
Mengevaluasi Model
Setelah pembuatan model, periksa akurasi menggunakan nilai aktual dan prediksi.
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
('Accuracy:', 0.90740740740740744)
Masalah Probabilitas Nol
Misalkan tidak ada tupel untuk pinjaman berisiko dalam dataset, dalam skenario ini, probabilitas posterior akan menjadi nol, dan model tidak dapat membuat prediksi. Masalah ini dikenal sebagai Probabilitas Nol karena kemunculan kelas tertentu adalah nol.
Solusi untuk masalah tersebut adalah koreksi Laplace atau Transformasi Laplace. Koreksi Laplacian adalah salah satu teknik smoothing. Di sini, Anda dapat mengasumsikan bahwa kumpulan data cukup besar sehingga menambahkan satu baris dari setiap kelas tidak akan membuat perbedaan dalam perkiraan probabilitas. Ini akan mengatasi masalah nilai probabilitas menjadi nol.
Sebagai Contoh: Misalkan untuk kelas pinjaman berisiko, ada 1000 tupel pelatihan dalam database. Dalam database ini, kolom pendapatan memiliki 0 tupel untuk pendapatan rendah, 990 tupel untuk pendapatan menengah, dan 10 tupel untuk pendapatan tinggi. Probabilitas kejadian ini, tanpa koreksi Laplacian, adalah 0, 0,990 (dari 990/1000), dan 0,010 (dari 10/1000)
Sekarang, terapkan koreksi Laplacian pada dataset yang diberikan. Mari tambahkan 1 tupel lagi untuk setiap pasangan nilai pendapatan. Probabilitas dari kejadian ini:
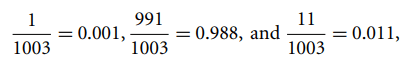
Keuntungan
- Ini bukan hanya pendekatan sederhana tetapi juga metode prediksi yang cepat dan akurat.
- Naive Bayes memiliki biaya komputasi yang sangat rendah.
- Ini dapat bekerja secara efisien pada kumpulan data yang besar.
- Ini berkinerja baik dalam kasus variabel respons diskrit dibandingkan dengan variabel kontinu.
- Ini dapat digunakan dengan beberapa masalah prediksi kelas.
- Ini juga berkinerja baik dalam kasus masalah analitik teks.
- Ketika asumsi independensi berlaku, pengklasifikasi Naive Bayes berkinerja lebih baik dibandingkan dengan model lain seperti regresi logistik.
Kekurangan
- Asumsi fitur independen. Dalam praktiknya, hampir tidak mungkin model akan mendapatkan seperangkat prediktor yang sepenuhnya independen.
- Jika tidak ada tupel pelatihan dari kelas tertentu, ini menyebabkan probabilitas posterior nol. Dalam hal ini, model tidak dapat membuat prediksi. Masalah ini dikenal sebagai Masalah Probabilitas/Frekuensi Nol.
Kesimpulan
Selamat, Anda telah mencapai akhir tutorial ini!
Dalam tutorial ini, Anda belajar tentang algoritma Naïve Bayes, cara kerjanya, asumsi Naive Bayes, masalah, implementasi, keuntungan, dan kerugian. Sepanjang jalan, Anda juga telah mempelajari pembuatan model dan evaluasi di scikit-learn untuk kelas biner dan multinomial.
Naive Bayes adalah algoritma yang paling mudah dan paling kuat. Terlepas dari kemajuan signifikan Pembelajaran Mesin dalam beberapa tahun terakhir, itu telah membuktikan nilainya. Ini telah berhasil digunakan di banyak aplikasi mulai dari analitik teks hingga mesin rekomendasi.




Tidak ada komentar:
Posting Komentar