Pengantar
Tujuan di balik seri tulisan ini adalah untuk menunjukkan betapa bermanfaatnya berbagai jenis algoritma R-CNN.

Dalam artikel ini, pertama-tama kita akan meringkas secara singkat apa yang kita pelajari di bagian 1, dan kemudian mendalami implementasi anggota tercepat dari keluarga R-CNN – Faster R-CNN.
Daftar isi
- Tinjauan singkat beberapa algoritma R-CNN untuk Deteksi Objek
- Memahami rumusan masalah
- Menyiapkan sistem
- Eksplorasi data
- Menerapkan Faster R-CNN
Tinjauan Singkat Beberapa Algoritma R-CNN untuk Deteksi Objek
Mari kita merangkum beberapa algoritma dalam keluarga R-CNN (R-CNN, Fast R-CNN, dan Faster R-CNN) yang kita lihat di artikel pertama. Ini akan membantu meletakkan dasar untuk bagian implementasi ketika akan memprediksi kotak pembatas (bounding boxes) yang ada dalam gambar yang ada di data baru tapi tidak ada di data lama.
R-CNN mengekstrak sekelompok wilayah dari gambar yang diberikan menggunakan pencarian selektif, dan kemudian memeriksa apakah salah satu kotak ini berisi objek. Kita pertama-tama mengekstrak wilayah ini, dan untuk setiap wilayah, CNN digunakan untuk mengekstrak fitur tertentu. Akhirnya, fitur-fitur ini kemudian digunakan untuk mendeteksi objek. Sayangnya, R-CNN menjadi agak lambat karena beberapa langkah yang terlibat dalam proses ini.
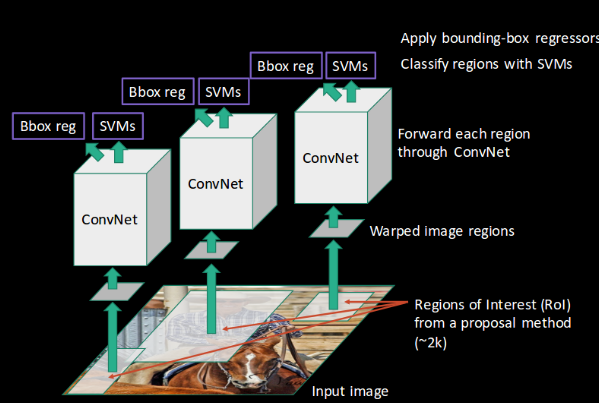
R-CNN
Fast R-CNN, di sisi lain, meneruskan seluruh gambar ke ConvNet yang menghasilkan daerah yang diinginkan (bukan meneruskan daerah yang diekstraksi dari gambar). Selain itu, alih-alih menggunakan tiga model berbeda (seperti yang kita lihat di R-CNN), ia menggunakan model tunggal yang mengekstrak fitur dari wilayah, mengklasifikasikannya ke dalam kelas yang berbeda, dan mengembalikan kotak pembatas.
Semua langkah ini dilakukan secara bersamaan, sehingga membuatnya lebih cepat dieksekusi dibandingkan dengan R-CNN. R-CNN cepat, bagaimanapun, tidak cukup cepat ketika diterapkan pada dataset besar karena juga menggunakan pencarian selektif untuk mengekstraksi wilayah.
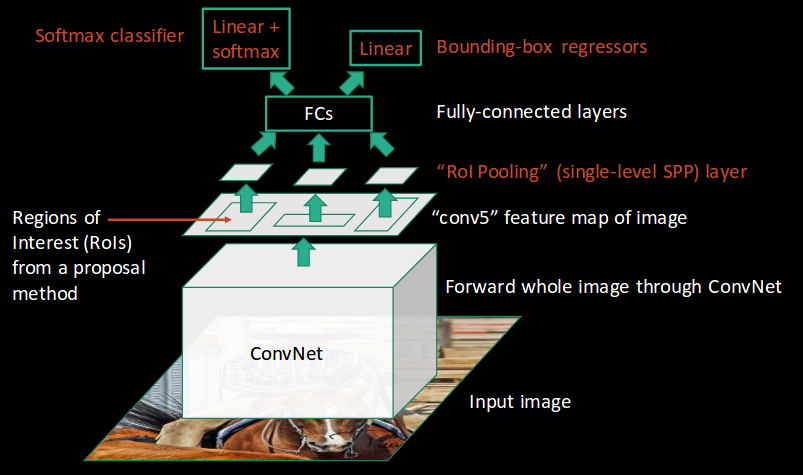
R-CNN cepat
R-CNN yang lebih cepat memperbaiki masalah pencarian selektif dengan menggantinya dengan Region Proposal Network (RPN). Kita pertama-tama mengekstrak peta fitur dari gambar input menggunakan ConvNet dan kemudian meneruskan peta tersebut melalui RPN yang mengembalikan proposal objek. Akhirnya, peta ini diklasifikasikan dan kotak pembatas diprediksi.
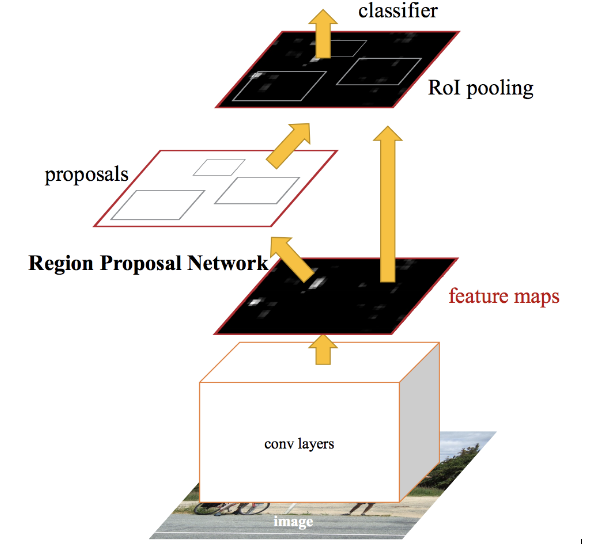
R-CNN lebih cepat
Saya telah merangkum di bawah ini langkah-langkah yang diikuti oleh algoritma R-CNN Lebih Cepat untuk mendeteksi objek dalam gambar:
- Ambil gambar input dan berikan ke ConvNet yang mengembalikan peta fitur untuk gambar
- Terapkan Jaringan Proposal Wilayah (RPN) pada peta fitur ini dan dapatkan proposal objek
- Terapkan lapisan penyatuan ROI untuk menurunkan semua proposal ke ukuran yang sama
- Terakhir, berikan proposal ini ke lapisan yang sepenuhnya terhubung untuk mengklasifikasikan kotak pembatas gambar apa pun yang diprediksi
Apa cara yang lebih baik untuk membandingkan algoritma yang berbeda ini selain dalam format tabel? Jadi di sini Anda pergi!
| algoritma | Fitur | Prediksi waktu / gambar | Keterbatasan |
| CNN | Membagi citra menjadi beberapa wilayah dan kemudian mengklasifikasikan setiap wilayah ke dalam berbagai kelas. | - | Membutuhkan banyak wilayah untuk memprediksi secara akurat dan karenanya waktu komputasi yang tinggi. |
| R-CNN | Menggunakan pencarian selektif untuk menghasilkan wilayah. Ekstrak sekitar 2000 wilayah dari setiap gambar. | 40-50 detik | Waktu komputasi yang tinggi karena setiap wilayah dilewatkan ke CNN secara terpisah. Juga, ia menggunakan tiga model berbeda untuk membuat prediksi. |
| Fast R-CNN | Setiap gambar dilewatkan hanya sekali ke CNN dan peta fitur diekstraksi. Pencarian selektif digunakan pada peta ini untuk menghasilkan prediksi. Menggabungkan ketiga model yang digunakan dalam R-CNN bersama-sama. | 2 detik | Pencarian selektif lambat dan karenanya waktu komputasi masih tinggi. |
| Faster R-CNN | Mengganti metode pencarian selektif dengan jaringan proposal wilayah (RPN) yang membuat algoritme lebih cepat. | 0,2 detik | Proposal objek membutuhkan waktu dan karena ada sistem yang berbeda yang bekerja satu demi satu, kinerja sistem tergantung pada kinerja sistem sebelumnya. |
Sekarang setelah kita memahami topik ini, saatnya untuk beralih dari teori ke bagian praktis dari artikel kita. Mari kita implementasikan Faster R-CNN menggunakan dataset dengan potensi aplikasi kehidupan nyata!
Memahami Rumusan Masalah
Kita akan mengerjakan kumpulan data terkait perawatan kesehatan dan tujuannya di sini adalah untuk memecahkan masalah Deteksi Sel Darah. Tugas kita adalah mendeteksi semua Sel Darah Merah - Red Blood Cell (RBC), Sel Darah Putih - White Blood Cell (WBC), dan Trombosit di setiap gambar yang diambil melalui pembacaan gambar mikroskopis. Di bawah ini adalah contoh seperti apa prediksi akhir kita:

Alasan memilih dataset ini adalah karena kepadatan sel darah merah, sel darah putih, dan Trombosit dalam aliran darah kita memberikan banyak informasi tentang sistem kekebalan dan hemoglobin. Ini dapat membantu mengidentifikasi apakah seseorang sehat atau tidak, dan jika ada perbedaan dalam darah mereka, tindakan dapat diambil dengan cepat untuk mendiagnosisnya.
Melihat sampel secara manual melalui mikroskop adalah proses yang membosankan. Dan di sinilah model Deep Learning memainkan peran penting. Mereka dapat mengklasifikasikan dan mendeteksi sel darah dari gambar mikroskopis dengan presisi yang mengesankan.
Dataset deteksi sel darah lengkap dapat diunduh dari sini. Perlu memodifikasi sedikit data untuk ruang lingkup artikel ini:
- Kotak pembatas telah dikonversi dari format .xml yang diberikan ke format .csv
- Membuat pemisahan set training testing pada seluruh dataset dengan memilih gambar secara acak untuk pemisahan
Perhatikan bahwa kita akan menggunakan framework Keras yang populer dengan backend TensorFlow di Python untuk melatih dan membangun model kita.
Menyiapkan Sistem
Sebelum kita benar-benar masuk ke fase pembuatan model, kita perlu memastikan bahwa pustaka dan kerangka kerja yang tepat telah diinstal. Pustaka di bawah ini diperlukan untuk menjalankan proyek ini:
- panda
- matplotlib
- aliran tensor
- keras – 2.0.3
- numpy
- opencv-python
- sklearn
- h5py
Sebagian besar pustaka yang disebutkan di atas sudah ada di mesin Anda jika Anda menginstal Anaconda dan Jupyter Notebooks. Selain itu, saya sarankan mengunduh file requirement.txt dari tautan ini dan menggunakannya untuk menginstal pustaka sisanya. Ketik perintah berikut di terminal:
pip install -r requirement.txt
Eksplorasi Data
Itu selalu ide yang baik (dan terus terang, langkah wajib) untuk terlebih dahulu mengeksplorasi data yang kita miliki. Ini membantu tidak hanya menemukan pola tersembunyi, tetapi juga mendapatkan wawasan keseluruhan yang berharga tentang apa yang sedang kita kerjakan. Tiga file yang saya buat dari seluruh dataset adalah:
- train_images: Gambar yang akan kita gunakan untuk melatih model. Kita memiliki kelas dan kotak pembatas sebenarnya untuk setiap kelas di folder ini.
- test_images: Gambar dalam folder ini akan digunakan untuk membuat prediksi menggunakan model terlatih. Set ini tidak memiliki kelas dan kotak pembatas untuk kelas-kelas ini.
- train.csv: Berisi nama, kelas dan koordinat kotak pembatas untuk setiap gambar. Mungkin ada beberapa baris untuk satu gambar karena satu gambar dapat memiliki lebih dari satu objek.
Mari kita baca file .csv (Anda dapat membuat file .csv sendiri dari dataset asli jika Anda ingin bereksperimen) dan mencetak beberapa baris pertama. Pertama-tama kita harus mengimpor perpustakaan di bawah ini untuk ini:
# mengimpor perpustakaan yang diperlukan impor panda sebagai pd impor matplotlib.pyplot sebagai plt %matplotlib sebaris dari patch impor matplotlib
# baca file csv menggunakan fungsi read_csv dari pandas kereta = pd.read_csv('kereta.csv') kereta.kepala()

Ada 6 kolom dalam file kereta. Mari kita pahami apa yang diwakili oleh setiap kolom:
- image_names: berisi nama gambar
- cell_type: menunjukkan jenis sel
- xmin: koordinat x dari bagian kiri bawah gambar
- xmax: koordinat x bagian kanan atas gambar
- ymin: koordinat y dari bagian kiri bawah gambar
- ymax: y-koordinat bagian kanan atas gambar
Sekarang mari kita mencetak gambar untuk memvisualisasikan apa yang sedang kita kerjakan:
# membaca gambar tunggal menggunakan fungsi imread matplotlib gambar = plt.imread('gambar/1.jpg') plt.imshow(gambar)

Seperti inilah gambaran sel darah. Di sini, bagian biru mewakili sel darah putih, dan bagian yang sedikit merah mewakili sel darah merah. Mari kita lihat berapa banyak gambar, dan jenis kelas yang berbeda, yang ada di set pelatihan kita.
# Jumlah gambar pelatihan unik melatih['image_names'].nunique()
Jadi, kita memiliki 254 gambar training.
# Jumlah kelas melatih['cell_type'].value_counts()

Kita memiliki tiga kelas sel yang berbeda, yaitu RBC, WBC dan Trombosit. Terakhir, mari kita lihat bagaimana gambar dengan objek yang terdeteksi akan terlihat seperti:
gambar = plt.figure() #tambahkan sumbu ke gambar kapak = fig.add_axes([0,0,1,1]) # baca dan plot gambarnya gambar = plt.imread('gambar/1.jpg') plt.imshow(gambar) # mengulangi gambar untuk objek yang berbeda untuk _,baris di kereta[train.image_names == "1.jpg"].iterrows(): xmin = baris.xmin xmax = baris.xmax ymin = baris.ymin ymax = baris.ymax lebar = xmax - xmin tinggi = ymax - ymin # tetapkan warna berbeda untuk kelas objek yang berbeda jika row.cell_type == 'RBC': warna tepi = 'r' ax.annotate('RBC', xy=(xmax-40,ymin+20)) elif row.cell_type == 'WBC': warna tepi = 'b' ax.annotate('WBC', xy=(xmax-40,ymin+20)) elif row.cell_type == 'Trombosit': warna tepi = 'g' ax.annotate('Trombosit', xy=(xmax-40,ymin+20)) # tambahkan kotak pembatas ke gambar rect = patch.Rectangle((xmin,ymin), width, height, edgecolor = edgecolor, facecolor = 'none') ax.add_patch(persegi)

Seperti inilah contoh pelatihannya. Kita memiliki kelas yang berbeda dan kotak pembatas yang sesuai. Sekarang mari kita latih model kita pada gambar-gambar ini. Kita akan menggunakan perpustakaan keras_frcnn untuk melatih model kita serta untuk mendapatkan prediksi pada gambar uji.
Menerapkan R-CNN yang Lebih Cepat
Untuk mengimplementasikan algoritma Faster R-CNN, kita akan mengikuti langkah-langkah yang disebutkan dalam repositori Github ini . Jadi sebagai langkah pertama, pastikan Anda mengkloning repositori ini. Buka jendela terminal baru dan ketik berikut ini untuk melakukan ini:
git clone https://github.com/kbardool/keras-frcnn.git
Pindahkan train_images dan test_images folder, serta train.csv file, untuk repositori kloning. Untuk melatih model pada dataset baru, format input harus:
jalur file,x1,y1,x2,y2,nama_kelasdi mana,
- filepath adalah jalur gambar pelatihan
- x1 adalah koordinat xmin untuk kotak pembatas
- y1 adalah koordinat ymin untuk kotak pembatas
- x2 adalah koordinat xmax untuk kotak pembatas
- y2 adalah koordinat ymax untuk kotak pembatas
- class_name adalah nama kelas di kotak pembatas itu
Kita perlu mengonversi format .csv menjadi file .txt yang akan memiliki format yang sama seperti yang dijelaskan di atas. Buat kerangka data baru, isi semua nilai sesuai format ke dalam kerangka data itu, lalu simpan sebagai file .txt.
data = pd.DataFrame() data['format'] = kereta['nama_gambar'] # karena gambar ada di folder train_images, tambahkan train_images sebelum nama gambar untuk saya dalam jangkauan(data.shape[0]): data['format'][i] = 'gambar_kereta/' + data['format'][i] # tambahkan xmin, ymin, xmax, ymax dan kelas sesuai format yang diperlukan untuk saya dalam jangkauan(data.shape[0]): data['format'][i] = data['format'][i] + ',' + str(train['xmin'][i]) + ',' + str(train['ymin'][ i]) + ',' + str(train['xmax'][i]) + ',' + str(train['ymax'][i]) + ',' + train['cell_type'][i ] data.to_csv('annotate.txt', header=Tidak ada, indeks=Tidak ada, sep=' ')
Apa berikutnya?
Kita akan menggunakan file train_frcnn.py untuk melatih model.
cd keras-frcnn python train_frcnn.py -o sederhana -p annotate.txt
Ini akan memakan waktu cukup lama untuk melatih model karena ukuran data. Jika memungkinkan, Anda dapat menggunakan GPU untuk mempercepat fase pelatihan. Anda juga dapat mencoba mengurangi jumlah epoch sebagai opsi alternatif. Untuk mengubah jumlah epoch, buka file train_frcnn.py di repositori kloning dan ubah parameter num_epochs .
Setiap kali model melihat peningkatan, bobot dari epoch tersebut akan disimpan dalam direktori yang sama dengan “ model_frcnn.hdf5 ”. Bobot ini akan digunakan ketika kita membuat prediksi pada set tes.
Mungkin perlu banyak waktu untuk melatih model dan mendapatkan bobot, tergantung pada konfigurasi mesin Anda. Saya sarankan menggunakan bobot yang saya dapatkan setelah melatih model selama sekitar 500 epoch. Anda dapat mengunduh bobot ini dari sini . Pastikan Anda menyimpan bobot ini di repositori kloning.
Jadi model kita telah dilatih dan bobotnya ditetapkan. Saatnya kita prediksi! Keras_frcnn membuat prediksi untuk gambar baru dan menyimpannya di folder baru. Kita hanya perlu membuat dua perubahan pada file test_frcnn.py untuk menyimpan gambar:
- Hapus komentar dari baris terakhir file ini:
cv2.imwrite('./results_imgs/{}.png'.format(idx),img) - Tambahkan komentar pada baris terakhir kedua dan ketiga terakhir dari file ini:
# cv2.imshow('img', img) # cv2.waitKey(0)
Mari kita membuat prediksi untuk gambar baru:
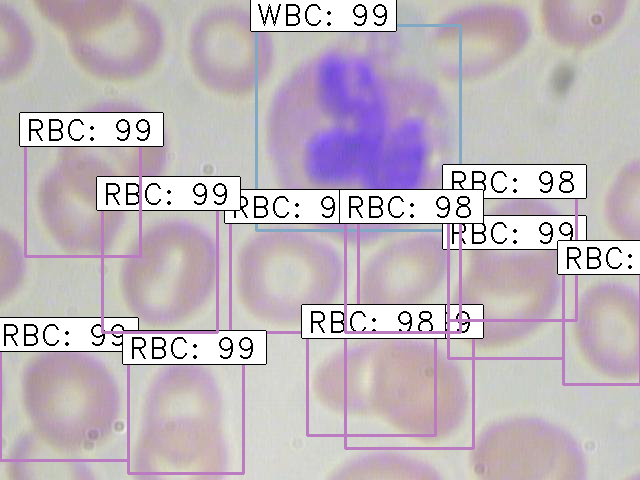
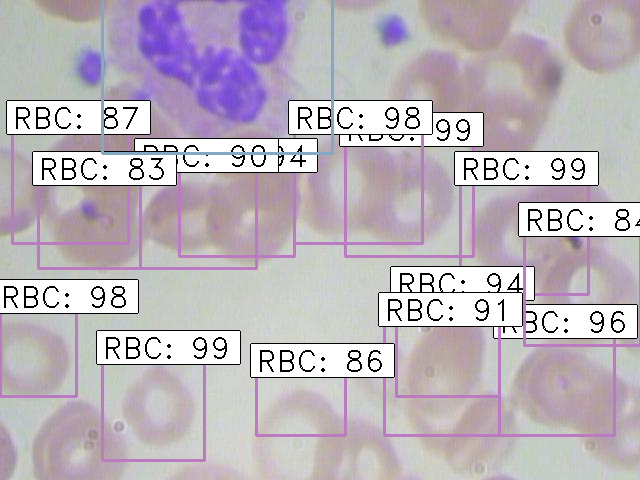
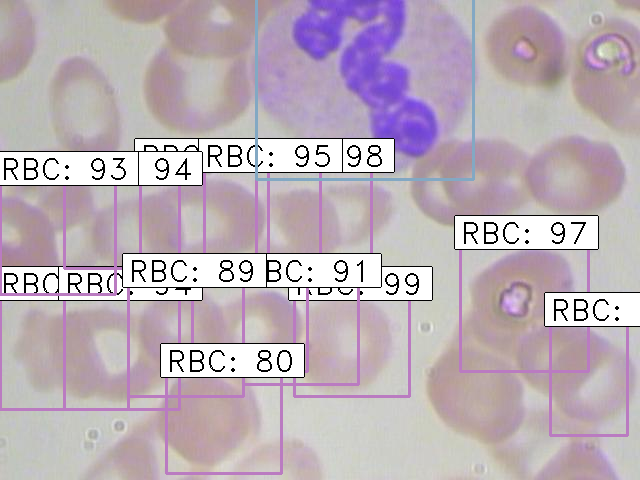
python test_frcnn.py -p test_imagesTerakhir, gambar dengan objek yang terdeteksi akan disimpan di folder “results_imgs”. Berikut adalah beberapa contoh prediksi yang saya dapatkan setelah menerapkan Faster R-CNN:
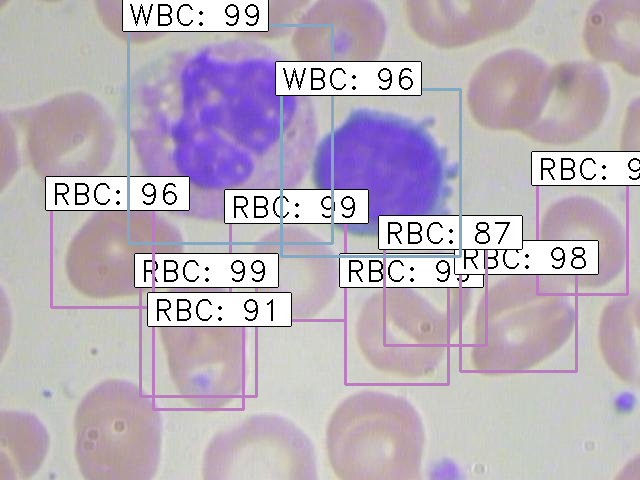
Hasil 1
Hasil 2
Hasil 3
Hasil 4
Catatan Akhir
Algoritma R-CNN benar-benar mutakhir untuk tugas deteksi objek. Ada lonjakan dalam beberapa tahun terakhir dalam jumlah aplikasi komputer visi yang dibuat, dan R-CNN adalah core sebagian besar dari mereka.
Keras_frcnn terbukti menjadi perpustakaan yang sangat baik untuk deteksi objek, dan selanjutnya kita akan fokus pada teknik yang lebih canggih seperti YOLO, SSD, dll.



Tidak ada komentar:
Posting Komentar