1. Cara Sederhana Menyelesaikan Tugas Deteksi Objek (menggunakan Deep Learning)
Gambar di bawah ini adalah contoh populer untuk mengilustrasikan cara kerja algoritma pendeteksian objek. Setiap objek dalam gambar, dari seseorang hingga layang-layang, telah ditemukan dan diidentifikasi dengan tingkat presisi tertentu.

Mari kita mulai dengan pendekatan deep learning yang paling sederhana, dan yang banyak digunakan, untuk mendeteksi objek dalam gambar – Convolutional Neural Networks atau CNN.
Perhatikan gambar di bawah ini:
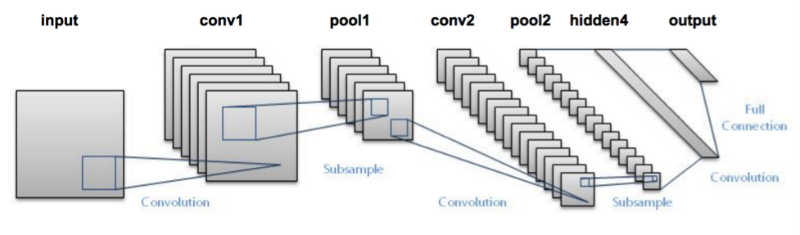
Kita meneruskan gambar ke network, dan kemudian dikirim melalui berbagai konvolusi dan pooling layers. Akhirnya, kita mendapatkan output dalam bentuk kelas objek.
Untuk setiap gambar input, kita mendapatkan kelas yang sesuai sebagai output. Bisakah kita menggunakan teknik ini untuk mendeteksi berbagai objek dalam sebuah gambar? Ya kita bisa! Mari kita lihat bagaimana kita dapat memecahkan masalah deteksi objek umum menggunakan CNN.
1. Pertama, kita ambil gambar sebagai input:

2. Kemudian membagi gambar menjadi berbagai wilayah:

3. Kemudian mempertimbangkan setiap wilayah sebagai gambar terpisah.
4. Lewatkan semua wilayah (gambar) ini ke CNN dan klasifikasikan ke dalam berbagai kelas.
5. Setelah kita membagi setiap wilayah ke dalam kelas yang sesuai, kita dapat menggabungkan semua wilayah ini untuk mendapatkan gambar asli dengan objek yang terdeteksi:

Masalah dengan menggunakan pendekatan ini adalah objek dalam gambar dapat memiliki rasio aspek dan lokasi spasial yang berbeda. Misalnya, dalam beberapa kasus objek mungkin menutupi sebagian besar gambar, sementara di lain pihak, objek mungkin hanya menutupi sebagian kecil dari gambar. Bentuk objek mungkin juga berbeda (banyak terjadi dalam kasus penggunaan kehidupan nyata).
Sebagai hasil dari faktor-faktor ini, kita akan membutuhkan sejumlah besar wilayah yang menghasilkan banyak waktu komputasi. Maka untuk mengatasi masalah ini dan mengurangi jumlah region, kita dapat menggunakan CNN berbasis region, yang memilih region menggunakan metode proposal. Mari kita pahami apa yang bisa dilakukan CNN berbasis wilayah.
2. Memahami Jaringan Saraf Konvolusi Berbasis Wilayah (Region-Based Convolutional Neural Network)
2.1 Intuisi RCNN
Alih-alih mengerjakan sejumlah besar wilayah, algoritma RCNN mengusulkan sekelompok kotak pada gambar dan memeriksa apakah salah satu kotak ini berisi objek apa pun. RCNN menggunakan pencarian selektif untuk mengekstrak kotak-kotak ini dari sebuah gambar (kotak-kotak ini disebut wilayah).
Pertama-tama mari kita pahami apa itu pencarian selektif dan bagaimana pencarian itu mengidentifikasi berbagai wilayah. Pada dasarnya ada empat wilayah yang membentuk suatu objek: varying scales, colors, textures, and enclosure. Pencarian selektif mengidentifikasi pola-pola ini dalam gambar dan mengusulkan berbagai wilayah berdasarkan itu. Berikut adalah ikhtisar singkat tentang cara kerja pencarian selektif (selective search):
- Pertama-tama mengambil gambar sebagai input:

- Kemudian, menghasilkan sub-segmentasi awal sehingga memiliki beberapa wilayah dari gambar ini:

- Teknik ini kemudian menggabungkan wilayah yang sama untuk membentuk wilayah yang lebih besar (berdasarkan kesamaan warna, kesamaan tekstur, kesamaan ukuran, dan kompatibilitas bentuk):

- Terakhir, daerah-daerah tersebut kemudian menghasilkan lokasi objek akhir (Region of Interest).
Di bawah ini adalah ringkasan singkat dari langkah-langkah yang diikuti di RCNN untuk mendeteksi objek:
- Pertama-tama menggunakan jaringan saraf convolutional yang telah dilatih sebelumnya.
- Kemudian, model ini dilatih ulang. Lapisan terakhir jaringan dilatih berdasarkan jumlah kelas yang perlu dideteksi.
- Langkah ketiga adalah mendapatkan Region of Interest untuk setiap gambar. Kemudian membentuk kembali semua wilayah ini sehingga mereka bisa cocok dengan ukuran input CNN.
- Setelah mendapatkan region, kita melatih SVM untuk mengklasifikasikan objek dan background. Untuk setiap kelas, kita melatih satu SVM biner.
- Terakhir, melatih model regresi linier untuk menghasilkan kotak pembatas yang lebih ketat untuk setiap objek yang diidentifikasi dalam gambar.
Anda mungkin mendapatkan ide yang lebih baik dari langkah-langkah di atas dengan contoh visual (Gambar untuk contoh yang ditunjukkan di bawah ini diambil dari jurnal ini ).
- Pertama, gambar diambil sebagai input:

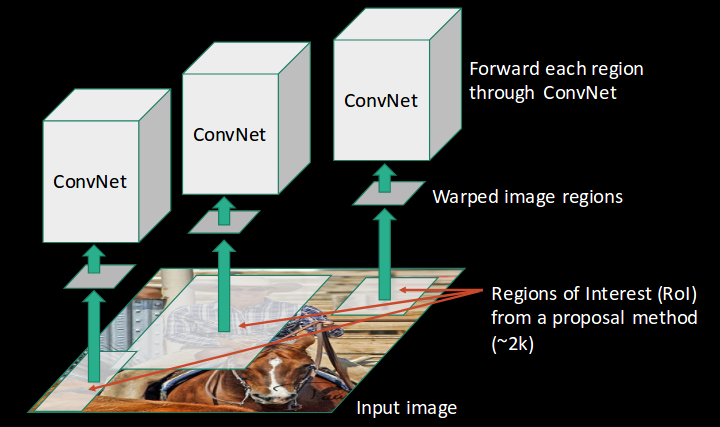
- Kemudian, kita mendapatkan Regions of Interest (ROI) menggunakan beberapa metode proposal (misalnya, pencarian selektif seperti yang terlihat di atas):

- Semua wilayah ini kemudian dibentuk kembali sesuai input CNN, dan setiap wilayah diteruskan ke ConvNet:
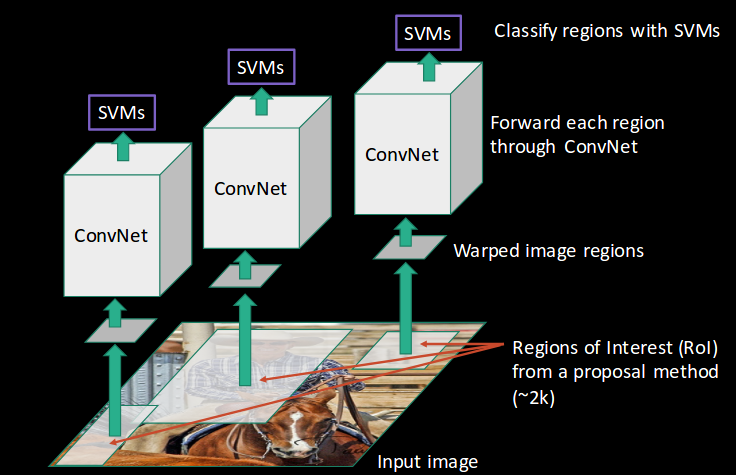
- CNN kemudian mengekstrak fitur untuk setiap wilayah dan SVM digunakan untuk membagi wilayah ini ke dalam kelas yang berbeda:
- Akhirnya, regresi kotak pembatas ( Bbox reg ) digunakan untuk memprediksi kotak pembatas untuk setiap wilayah yang diidentifikasi:
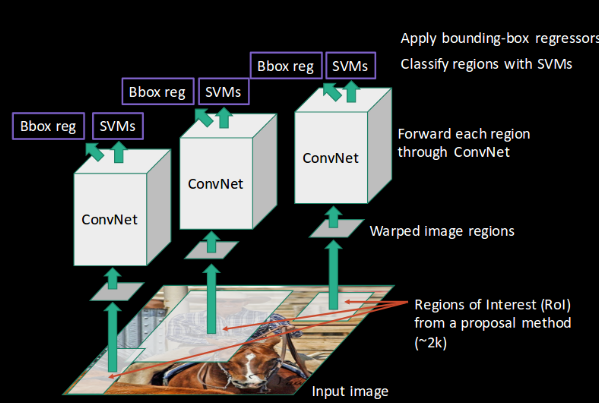
Dan ini, singkatnya, adalah bagaimana RCNN membantu kita mendeteksi objek.
2.2 Masalah dengan RCNN
Sejauh ini, kita telah melihat bagaimana RCNN dapat membantu untuk deteksi objek. Tetapi teknik ini hadir dengan keterbatasannya sendiri. Pelatihan model RCNN mahal dan lambat berkat langkah-langkah di bawah ini:
- Mengekstrak 2.000 wilayah untuk setiap gambar berdasarkan pencarian selektif
- Ekstraksi fitur menggunakan CNN untuk setiap wilayah gambar. Misalkan kita memiliki N gambar, maka jumlah fitur CNN akan menjadi N*2.000
- Seluruh proses pendeteksian objek menggunakan RCNN memiliki tiga model:
- CNN untuk ekstraksi fitur
- Pengklasifikasi SVM linier untuk mengidentifikasi objek
- Model regresi untuk mengencangkan kotak pembatas.
Semua proses ini bergabung untuk membuat RCNN sangat lambat. Dibutuhkan sekitar 40-50 detik untuk membuat prediksi untuk setiap gambar baru, yang pada dasarnya membuat model menjadi rumit dan praktis tidak mungkin dibuat ketika dihadapkan dengan kumpulan data raksasa.
Inilah kabar baiknya – kita memiliki teknik pendeteksian objek lain yang memperbaiki sebagian besar keterbatasan RCNN.
3. Memahami Fast RCNN
3.1 Intuisi Fast RCNN
Apa lagi yang bisa kita lakukan untuk mengurangi waktu komputasi yang biasanya dibutuhkan oleh algoritma RCNN? Alih-alih menjalankan CNN 2.000 kali per gambar, kita dapat menjalankannya hanya sekali per gambar dan mendapatkan semua wilayah yang diinginkan (wilayah yang berisi beberapa objek).
Ross Girshick, penulis RCNN, muncul dengan ide menjalankan CNN hanya sekali per gambar dan kemudian menemukan cara untuk membagikan perhitungan itu di 2.000 wilayah. Di Fast RCNN, kami memasukkan gambar input ke CNN, yang pada gilirannya menghasilkan peta fitur konvolusi. Dengan menggunakan peta ini, wilayah proposal diekstraksi. Kemudian menggunakan lapisan penyatuan RoI untuk membentuk kembali semua wilayah yang diusulkan menjadi ukuran tetap, sehingga dapat dimasukkan ke dalam jaringan yang terhubung sepenuhnya.
Mari kita uraikan ini menjadi langkah-langkah untuk menyederhanakan konsep:
- Seperti dua teknik sebelumnya, kita mengambil gambar sebagai input.
- Gambar ini diteruskan ke ConvNet yang pada gilirannya menghasilkan Wilayah yang Diinginkan.
- Lapisan penyatuan RoI diterapkan pada semua wilayah ini untuk membentuknya kembali sesuai dengan input ConvNet. Kemudian, setiap wilayah diteruskan ke jaringan yang sepenuhnya terhubung.
- Lapisan softmax digunakan di atas jaringan yang sepenuhnya terhubung ke kelas output. Seiring dengan lapisan softmax, lapisan regresi linier juga digunakan secara paralel untuk menghasilkan koordinat kotak pembatas untuk kelas yang diprediksi.
Jadi, alih-alih menggunakan tiga model berbeda (seperti di RCNN), Fast RCNN menggunakan model tunggal yang mengekstrak fitur dari wilayah, membaginya ke dalam kelas yang berbeda, dan mengembalikan kotak batas untuk kelas yang diidentifikasi secara bersamaan.
Untuk memecah ini lebih jauh, saya akan memvisualisasikan setiap langkah untuk menambahkan sudut praktis pada penjelasannya.
- Kami mengikuti langkah yang sekarang terkenal untuk mengambil gambar sebagai input:

- Gambar ini diteruskan ke ConvNet yang mengembalikan wilayah minat yang sesuai:

- Kemudian kami menerapkan lapisan penyatuan RoI pada wilayah yang diekstraksi untuk memastikan semua wilayah memiliki ukuran yang sama:

- Akhirnya, wilayah ini diteruskan ke jaringan yang sepenuhnya terhubung yang mengklasifikasikannya, serta mengembalikan kotak pembatas menggunakan softmax dan lapisan regresi linier secara bersamaan:
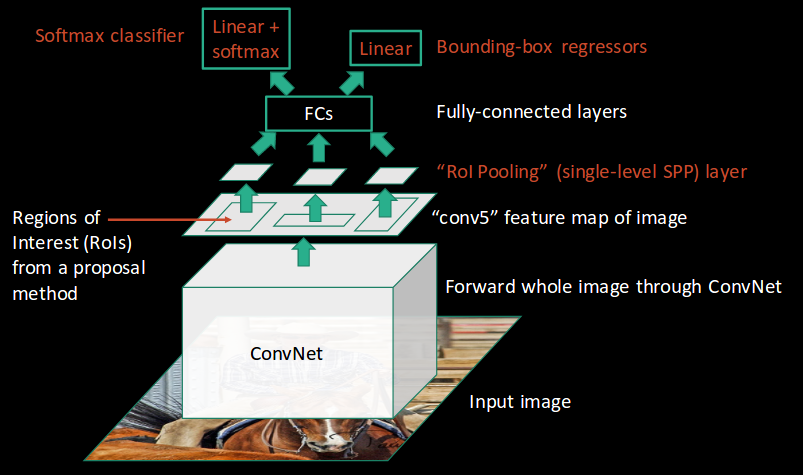
Beginilah cara Fast RCNN menyelesaikan dua masalah utama RCNN, yaitu, meneruskan satu alih-alih 2.000 wilayah per gambar ke ConvNet, dan menggunakan satu alih-alih tiga model berbeda untuk mengekstraksi fitur, klasifikasi, dan menghasilkan kotak pembatas.
3.2 Masalah dengan Fast RCNN
Tetapi bahkan Fast RCNN memiliki area masalah tertentu. Ini juga menggunakan pencarian selektif sebagai metode proposal untuk menemukan Wilayah yang Diinginkan, yang merupakan proses yang lambat dan memakan waktu. Dibutuhkan sekitar 2 detik per gambar untuk mendeteksi objek, yang jauh lebih baik dibandingkan dengan RCNN. Tetapi ketika mempertimbangkan kumpulan data kehidupan nyata yang besar, bahkan Fast RCNN tidak terlihat begitu cepat lagi.
Tapi ada algoritma pendeteksi objek lain yang mengalahkan Fast RCNN: Faster RCNN.
4. Memahami Faster RCNN
4.1. Intuisi Faster RCNN
Faster RCNN adalah versi modifikasi dari Fast RCNN. Perbedaan utama di antara mereka adalah Fast RCNN menggunakan pencarian selektif untuk menghasilkan Regions of Interest, sedangkan Faster RCNN menggunakan "Region Proposal Network", alias RPN. RPN mengambil peta fitur gambar sebagai input dan menghasilkan satu set proposal objek, masing-masing dengan skor objektivitas sebagai output.
Langkah-langkah di bawah ini biasanya diikuti dalam pendekatan RCNN yang Lebih Cepat:
- Mengambil gambar sebagai input dan meneruskannya ke ConvNet yang mengembalikan peta fitur untuk gambar itu.
- Jaringan proposal wilayah diterapkan pada peta fitur ini. Ini mengembalikan proposal objek bersama dengan skor objektivitasnya.
- Lapisan penyatuan RoI diterapkan pada proposal ini untuk menurunkan semua proposal ke ukuran yang sama.
- Akhirnya, proposal diteruskan ke lapisan yang terhubung penuh yang memiliki lapisan softmax dan lapisan regresi linier di atasnya, untuk mengklasifikasikan dan menampilkan kotak pembatas untuk objek.
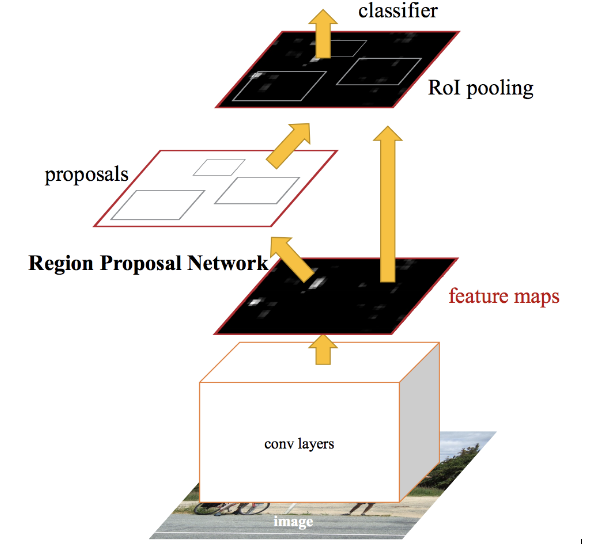
Bagaimana Jaringan Proposal Wilayah (RPN) ini bekerja?
Untuk memulainya, Faster RCNN mengambil peta fitur dari CNN dan meneruskannya ke Jaringan Proposal Wilayah (Region Proposal Network). RPN menggunakan sliding windowr di setiap peta fitur, dan di setiap jendela, ini menghasilkan k Anchor boxes dengan berbagai bentuk dan ukuran:
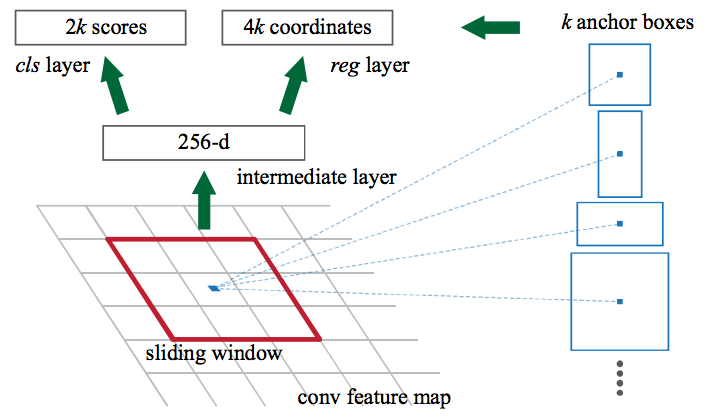
Anchor boxes adalah kotak batas berukuran tetap yang ditempatkan di seluruh gambar dan memiliki bentuk dan ukuran yang berbeda. Untuk setiap anchor, RPN memprediksi dua hal:
- Yang pertama adalah probabilitas bahwaAnchor box adalah objek (tidak mempertimbangkan kelas mana objek itu berasal)
- Kedua adalah regressor kotak pembatas untuk menyesuaikan Anchor boxes agar lebih sesuai dengan objek
Kita sekarang memiliki kotak pembatas dengan berbagai bentuk dan ukuran yang diteruskan ke lapisan penyatuan RoI. Sekarang mungkin saja setelah langkah RPN, ada proposal tanpa kelas yang ditugaskan padanya. Kita dapat mengambil setiap proposal dan memotongnya sehingga setiap proposal berisi objek. Inilah yang dilakukan lapisan penyatuan RoI. Ini mengekstrak peta fitur berukuran tetap untuk setiap Anchor boxes:
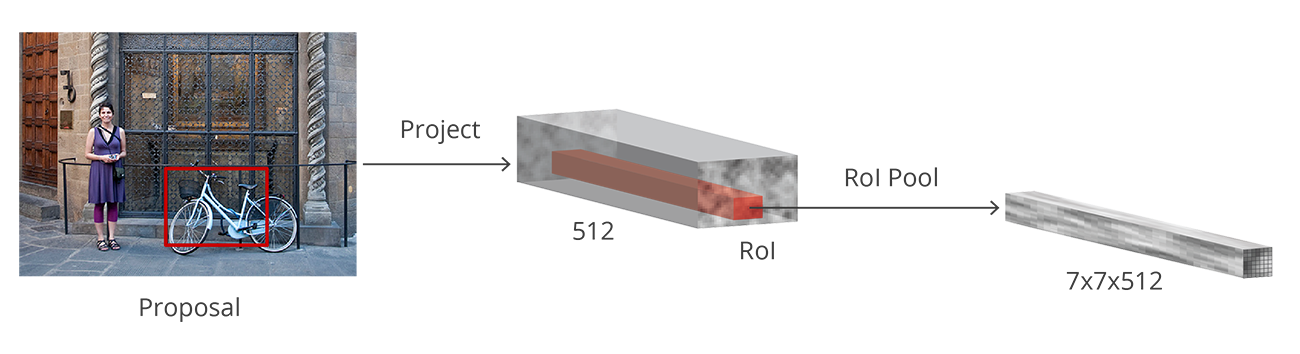
Kemudian peta fitur ini diteruskan ke lapisan yang terhubung penuh yang memiliki lapisan softmax dan regresi linier. Akhirnya mengklasifikasikan objek dan memprediksi kotak pembatas untuk objek yang diidentifikasi.
4.2 Masalah dengan RCNN yang Lebih Cepat
Semua algoritma deteksi objek yang telah kita bahas sejauh ini menggunakan wilayah untuk mengidentifikasi objek. Jaringan tidak melihat gambar lengkap sekaligus, tetapi berfokus pada bagian-bagian gambar secara berurutan. Ini menciptakan dua komplikasi:
- Algoritma membutuhkan banyak lintasan melalui satu gambar untuk mengekstrak semua objek
- Karena ada sistem berbeda yang bekerja satu demi satu, kinerja sistem lebih jauh ke depan tergantung pada bagaimana kinerja sistem sebelumnya
5. Ringkasan Algoritma yang dibahas
Tabel di bawah ini adalah ringkasan bagus dari semua algoritma yang telah di bahas dalam artikel ini.
| algoritma | Fitur | Prediksi waktu / gambar | Keterbatasan |
| CNN | Membagi citra menjadi beberapa region kemudian mengklasifikasikan setiap region ke dalam berbagai kelas. | - | Membutuhkan banyak wilayah untuk memprediksi secara akurat dan karenanya waktu komputasi yang tinggi. |
| RCNN | Menggunakan pencarian selektif untuk menghasilkan wilayah. Ekstrak sekitar 2000 wilayah dari setiap gambar. | 40-50 detik | Waktu komputasi yang tinggi karena setiap region dilewatkan ke CNN secara terpisah serta menggunakan tiga model yang berbeda untuk membuat prediksi. |
| Fast RCNN | Setiap gambar dilewatkan hanya sekali ke CNN dan peta fitur diekstraksi. Pencarian selektif digunakan pada peta ini untuk menghasilkan prediksi. Menggabungkan ketiga model yang digunakan dalam RCNN bersama-sama. | 2 detik | Pencarian selektif lambat dan karenanya waktu komputasi masih tinggi. |
| Faster RCNN | Mengganti metode pencarian selektif dengan jaringan proposal wilayah yang membuat algoritme lebih cepat. | 0,2 detik | Proposal objek membutuhkan waktu dan karena ada sistem yang berbeda yang bekerja satu demi satu, kinerja sistem tergantung pada kinerja sistem sebelumnya. |

Tidak ada komentar:
Posting Komentar