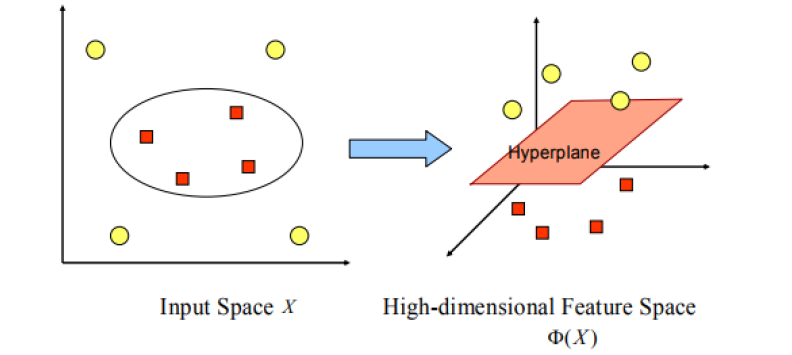
SVM merupakan salah satu metode klasifikasi dalam data mining. SVM juga dapat melakukan prediksi baik pada klasifikasi maupun regresi. Pada dasarnya SVM memiliki prinsip linear, akan tetapi kini SVM telah berkembang sehingga dapat bekerja pada masalah non-linear. Cara kerja SVM pada masalah non-linear adalah dengan memasukkan konsep kernel pada ruang berdimensi tinggi. Pada ruang yang berdimensi ini, nantinya akan dicari pemisah atau yang sering disebut hyperplane. Hyperplane dapat memaksimalkan jarak atau margin antara kelas data. Hyperplane terbaik antara kedua kelas dapat ditemukan dengan mengukur margin dan kemudian mencari titik maksimalnya. Usaha dalam mencari hyperplane yang terbaik sebagai pemisah kelas kelas adalah inti dari proses pada metode SVM.

Berikut ini merupakan beberapa fungsi kernel pada umumnya:
- Kernel Polynomial dengan Variabel Bebas q
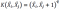
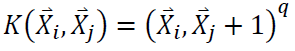
- Kernel Gaussian atau RBF
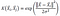
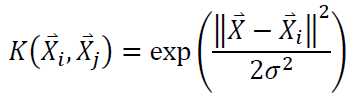
Penerapan SVM
Nah, langsung aja ya kita masuk ke penerapan SVM untuk klasifikasi data pasien Penyakit Kanker Payudara. Datanya berupa rata-rata dari karakteristik yang diambil sampelnya dari tubuh pasien yang sedang didiagnosis.
Oke, langkah pertama yang kita lakukan adalah memuat data penyakit kanker payudara ke dalam notebook menggunakan sintaks berikut:
#Import scikit-learn dataset library
from sklearn import datasets#Load dataset
cancer = datasets.load_breast_cancer()
Kemudian kita eksplor data untuk mengetahui variabel features/independen dan nama target.
# print the names of the 13 features
print("Features: ", cancer.feature_names)# print the label type of cancer('malignant' 'benign')
print("Labels: ", cancer.target_names)


Setelah itu kita akan cek dimensi datanya menggunakan sintaks berikut:
# print data(feature)shape
cancer.data.shape
Data memiliki 569 baris dan 30 kolom. Kemudian kita akan lihat 5 data pertama dari variabel features.
print(cancer.data[0:5])

# print the cancer labels (0:malignant, 1:benign)
print(cancer.target)

Selanjutnya, kita akan membagi dataset menjadi data training dan data testing. Data training yang digunakan adalah sebanyak 75% dan data testing sebanyak 25%.
# Import train_test_split function
from sklearn.model_selection import train_test_split# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.25,random_state=123) # 75% training and 25% test
Kemudian, kita akan membuat model yang akan kita gunakan untuk melakukan klasifikasi.
#Import svm model
from sklearn import svm#Create a svm Classifier
clf = svm.SVC(kernel='linear') # Linear Kernel#Train the model using the training sets
clf.fit(X_train, y_train)#Predict the response for test dataset
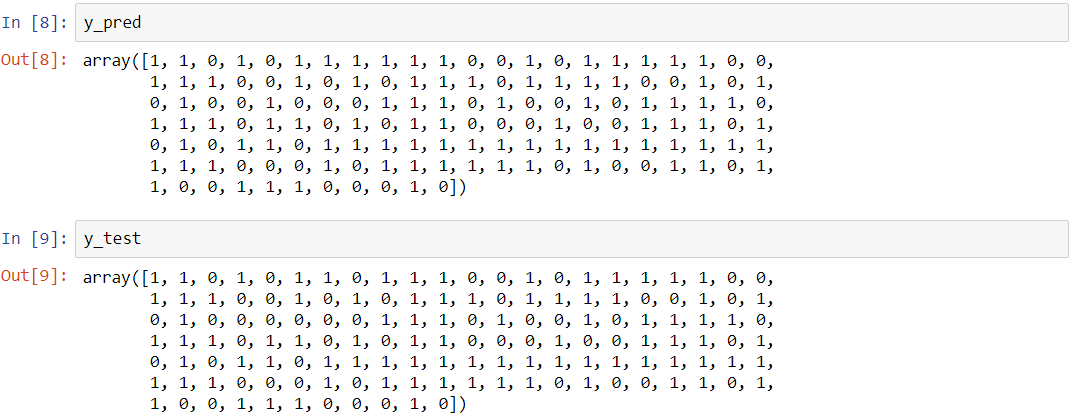
y_pred = clf.predict(X_test)

Langkah berikutnya adalah melihat confusion matrix untuk memudahkan dalam mengetahui apakah terdapat kesalahan dalam pengklasifikasian.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)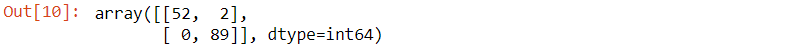
Berdasarkan output, diketahui bahwa terdapat 2 kesalahan dalam pengklasifikasian menggunakan algoritma SVM, yaitu 2 pasien diklasifikasikan dalam pasien pengidap kanker jinak, tetapi dalam keadaan sebenarnya, pasien mengalami kanker ganas.
Kemudian kita akan melihat akurasi dari hasil pengklasifikasian menggunakan algoritma SVM. Akurasi merupakan proporsi jumlah prediksi benar.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
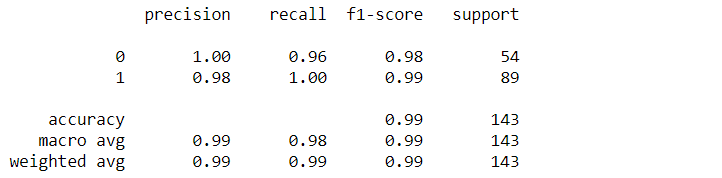
Akurasi yang diperoleh adalah sebesar 99%. Hasil ini bisa dikatakan sebagai hasil yang sangat bagus.




Tidak ada komentar:
Posting Komentar